



Big Tech bị phạt 3,5 tỷ USD vì AI và dữ liệu cá nhân
Báo cáo công bố ngày 22/6 của Surfshark chỉ ra rằng 9 trong số 10 khoản phạt liên quan đến trí tuệ nhân tạo mà các ông lớn công nghệ phải trả đều xuất phát từ việc sử dụng dữ liệu cá nhân trái phép.
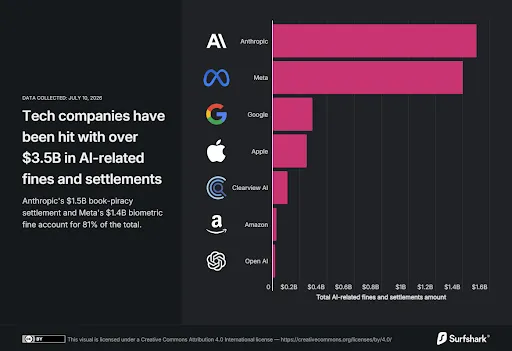
Biểu đồ báo cáo vi phạm quy định về AI. Theo nghiên cứu của Surfshark, Clearview AI là công ty đầu tiên bị phạt tổng cộng khoảng 46 triệu đô la vào năm 2022 vì thu thập hình ảnh khuôn mặt cho cơ sở dữ liệu nhận dạng khuôn mặt của mình. Nhưng tốc độ đã tăng lên vào năm 2024, với 5 khoản phạt riêng biệt mới được áp đặt lên Google, OpenAI, Meta, Clearview và Amazon. Nguồn ảnh: Surfhsark
Big Tech phải trả 3,5 tỷ USD tiền phạt và dàn xếp pháp lý kể từ năm 2022
Theo báo cáo của Surfshark, từ năm 2022 đến nay đã có 10 vụ xử phạt hoặc dàn xếp pháp lý lớn liên quan đến AI với tổng giá trị khoảng 3,5 tỷ USD.
Báo cáo cho biết 9 trong số 10 vụ việc liên quan đến các vấn đề về quyền riêng tư hoặc việc xử lý dữ liệu cá nhân, cho thấy dữ liệu đang trở thành một trong những mặt trận pháp lý lớn nhất của ngành AI.
Các doanh nghiệp xuất hiện trong báo cáo gồm Anthropic, Meta, Google, Apple, Amazon, OpenAI và Clearview AI.
Anthropic và Meta chịu khoản bồi thường lớn nhất
Theo Surfshark, Anthropic là doanh nghiệp có khoản bồi thường lớn nhất, lên tới 1,5 tỷ USD, trong vụ kiện liên quan đến việc sử dụng sách có bản quyền để huấn luyện mô hình AI Claude.
Đứng thứ hai là Meta với khoản phạt 1,4 tỷ USD liên quan đến việc thu thập và sử dụng dữ liệu sinh trắc học của người dùng trong công nghệ nhận diện khuôn mặt mà không có sự đồng ý hợp pháp.
Google nằm trong báo cáo của Surfshark với khoản xử lý khoảng 291 triệu USD liên quan đến việc sử dụng nội dung truyền thông và dữ liệu trong các dịch vụ AI.
Trong khi đó, Apple chấp nhận khoản dàn xếp pháp lý 250 triệu USD sau các tranh chấp liên quan đến việc quảng bá tính năng Apple Intelligence.
Clearview AI chịu tổng cộng khoảng 105 triệu USD tiền phạt qua nhiều vụ việc liên quan đến cơ sở dữ liệu nhận diện khuôn mặt. Amazon bị phạt 25 triệu USD vì lưu giữ dữ liệu giọng nói trẻ em thu thập từ Alexa trái quy định. OpenAI từng bị cơ quan bảo vệ dữ liệu của Ý phạt khoảng 17 triệu USD, tuy nhiên quyết định này sau đó đã bị tòa án hủy bỏ.

Trí tuệ nhân tạo (AI) có thể biết rất nhiều về bạn chỉ dựa trên các mô hình quảng cáo tổng thể mà bạn xem, mà không cần truy cập vào lịch sử duyệt web hoặc dữ liệu cá nhân của bạn. Ảnh: Getty
Dữ liệu đang trở thành "mặt trận" mới của cuộc đua AI
Nếu sức mạnh tính toán là "động cơ" của AI, thì dữ liệu chính là "nhiên liệu". Sự bùng nổ của các mô hình AI tạo sinh trong vài năm qua đã kéo theo nhu cầu chưa từng có về dữ liệu để huấn luyện, từ văn bản, hình ảnh, âm thanh cho đến video. Chính cơn khát dữ liệu ấy đang đẩy ngành công nghệ vào một cuộc đối đầu ngày càng gay gắt với các quy định về quyền riêng tư, bản quyền và quyền kiểm soát dữ liệu cá nhân.
Theo Surfshark, phần lớn các vụ xử phạt liên quan đến AI trong những năm gần đây đều xuất phát từ cách doanh nghiệp thu thập, xử lý hoặc sử dụng dữ liệu. Đây là tín hiệu cho thấy trọng tâm của cuộc đua AI không còn chỉ nằm ở việc phát triển những mô hình mạnh hơn, mà còn ở việc chứng minh nguồn dữ liệu được sử dụng là hợp pháp và minh bạch.
Báo cáo cũng cảnh báo rằng làn sóng xử phạt hiện nay có thể mới chỉ là bước khởi đầu. Trong khi AI phát triển với tốc độ rất nhanh, khung pháp lý tại nhiều quốc gia vẫn đang trong quá trình hoàn thiện.
Khi các quy định về AI, bảo vệ dữ liệu cá nhân và bản quyền dần được siết chặt, các cuộc điều tra, kiện tụng và xử phạt đối với doanh nghiệp công nghệ nhiều khả năng sẽ gia tăng.
Điều đó đồng nghĩa chi phí pháp lý và chi phí tuân thủ sẽ trở thành một phần không thể thiếu trong chiến lược phát triển AI. Nếu trước đây các công ty cạnh tranh bằng quy mô mô hình, năng lực tính toán và tốc độ đổi mới, thì ở giai đoạn tiếp theo, lợi thế có thể thuộc về những doanh nghiệp sở hữu nguồn dữ liệu được cấp phép đầy đủ và có khả năng chứng minh tính hợp pháp trong toàn bộ quy trình huấn luyện AI.
Đối với người dùng, đây cũng là lời nhắc rằng dữ liệu cá nhân đang trở thành một trong những tài sản giá trị nhất của kỷ nguyên AI. Mỗi bài đăng, bức ảnh hay đoạn văn được chia sẻ trên Internet không chỉ phục vụ các dịch vụ trực tuyến, mà còn có thể trở thành nguyên liệu để phát triển các mô hình trí tuệ nhân tạo.
Vì vậy, câu hỏi "AI thông minh đến đâu?" đang dần được thay thế bằng một câu hỏi quan trọng không kém: "AI đã học từ dữ liệu của ai và bằng cách nào?".




Bình luận
Thông báo
Bạn đã gửi thành công.
Đăng nhập để tham gia bình luận
Đăng nhập với
Facebook Google