



Cuộc chiến về quyền riêng tư của người dùng AI

Mặc dù có những lo ngại ngày càng tăng về các mô hình AI, nghiên cứu mới cho thấy nỗi sợ hãi về quyền riêng tư dữ liệu đối với người dùng có thể bị thổi phồng. Thực tế, chatbot AI nào hiện nay thu thập nhiều thông tin cá nhân hơn?
Nghiên cứu mới cho thấy nỗi lo về quyền riêng tư dữ liệu có thể bị thổi phồng.
Sự ra mắt của mô hình AI nguồn mở hàng đầu DeepSeek vào tháng 1/2025 đã gây chấn động trong ngành công nghệ toàn cầu. Với 12 triệu lượt tải xuống chỉ trong hai ngày, DeepSeek nhanh chóng trở thành hiện tượng.
Tuy nhiên, lo ngại về quyền riêng tư và bảo mật đã dẫn đến lệnh cấm sử dụng DeepSeek tại nhiều quốc gia, đặc biệt là ở Mỹ. Nhưng liệu DeepSeek có thực sự là mối đe dọa lớn nhất đối với quyền riêng tư của người dùng?
Hầu hết các chatbot đều thu thập dữ liệu người dùng
Theo nghiên cứu mới từ Surfshark, Google Gemini là chatbot AI thu thập nhiều dữ liệu người dùng nhiều nhất.
Nghiên cứu này phân tích chính sách quyền riêng tư của 10 chatbot AI phổ biến trên Apple App Store, bao gồm ChatGPT, Gemini, Copilot, Perplexity, DeepSeek, Grok, Jasper, Poe, Claude và Pi. Kết quả cho thấy Gemini thu thập tới 22/35 loại dữ liệu người dùng, bao gồm cả thông tin nhạy cảm như vị trí, nội dung, danh bạ và lịch sử duyệt web. DeepSeek đứng thứ 5 trong danh sách này. Danh sách cũng cho thấy, không có chatbot AI nào mà không thu thập dữ thiệu thông tin người dùng.
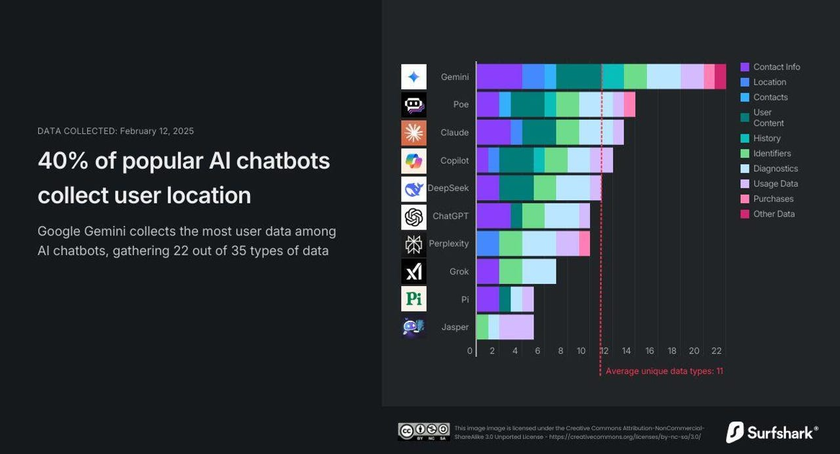
Kết quả nghiên cứu và xếp hạng của Surfshark.
Gemini, Copilot và Perplexity là những chatbot được xác định thu thập dữ liệu vị trí chính xác. Đáng chú ý, khoảng 30% chatbot chia sẻ dữ liệu nhạy cảm của người dùng, bao gồm vị trí và lịch sử duyệt web, với các bên thứ ba như nhà môi giới dữ liệu.
Copilot, Poe và Jasper cũng theo dõi dữ liệu người dùng, liên kết dữ liệu thu thập được từ ứng dụng với dữ liệu của bên thứ ba cho mục đích quảng cáo có mục tiêu hoặc đo lường quảng cáo. Cụ thể, Copilot và Poe thu thập ID thiết bị, trong khi Jasper thu thập ID thiết bị, dữ liệu tương tác sản phẩm, dữ liệu quảng cáo và "bất kỳ dữ liệu nào khác về hoạt động của người dùng trong ứng dụng".
Mối lo ngại về quyền riêng tư của người dùng AI có thực sự đáng sợ?
Trong khi nhiều chatbot bị chỉ trích vì lo ngại về quyền riêng tư, thực tế cho thấy mô hình DeepSeek R1 thu thập 11 loại dữ liệu, chủ yếu là thông tin liên hệ, nội dung người dùng và chẩn đoán. ChatGPT là chatbot thu thập 10 loại dữ liệu, bao gồm thông tin liên lạc, nội dung người dùng, mã định danh, dữ liệu sử dụng và chẩn đoán.
Trong số đó, DeepSeek cũng cho phép người dùng quản lý và xóa lịch sử trò chuyện trong cài đặt, một tính năng không tìm thấy ở các chatbot khác.

Mặt khác, những lo ngại về quyền riêng tư xung quanh DeepSeek phần lớn xuất phát từ rủi ro bị giám sát, chiến tranh mạng và an ninh quốc gia đối với công chúng Mỹ. Chính sách bảo mật của DeepSeek tiết lộ rằng thông tin cá nhân thu thập từ người dùng có thể được lưu trữ trên các máy chủ đặt tại Trung Quốc. Điều này đã làm dấy lên nghi ngại về việc dữ liệu người dùng có thể bị chính phủ của họ tiếp cận.
Cuộc đua AI và rủi ro toàn cầu
Cuộc đua AI giữa Mỹ và Trung Quốc đang đặt ra những thách thức nghiêm trọng về quyền riêng tư, an ninh và đạo đức. Trong khi các công ty Mỹ như Google và Microsoft thu thập lượng dữ liệu khổng lồ từ người dùng, các sản phẩm AI của Trung Quốc như DeepSeek lại bị xem là mối đe dọa lớn hơn do lo ngại về sự can thiệp của chính phủ.

Trong bối cảnh cuộc đua AI toàn cầu, việc bảo vệ quyền riêng tư của người dùng là ưu tiên hàng đầu. Tuy nhiên, những lo ngại về an ninh quốc gia có thể che lấp sự thật rằng các chatbot đều thu thập dữ liệu người dùng theo các cách khác nhau, không có ngoại lệ.
Thay vì tập trung vào một sản phẩm cụ thể, cần có sự hợp tác toàn cầu để thiết lập các tiêu chuẩn bảo mật và đạo đức trong lĩnh vực AI, đảm bảo rằng công nghệ này được phát triển một cách có trách nhiệm và minh bạch.



Bình luận
Thông báo
Bạn đã gửi thành công.
Đăng nhập để tham gia bình luận
Đăng nhập với
Facebook Google